I managed to make a website using Axum, a web framework for Rust, pretty similar to Flask in its minimalistic approach. Although it's a basic site, I'm happy with the result, and I learned a lot in the process.
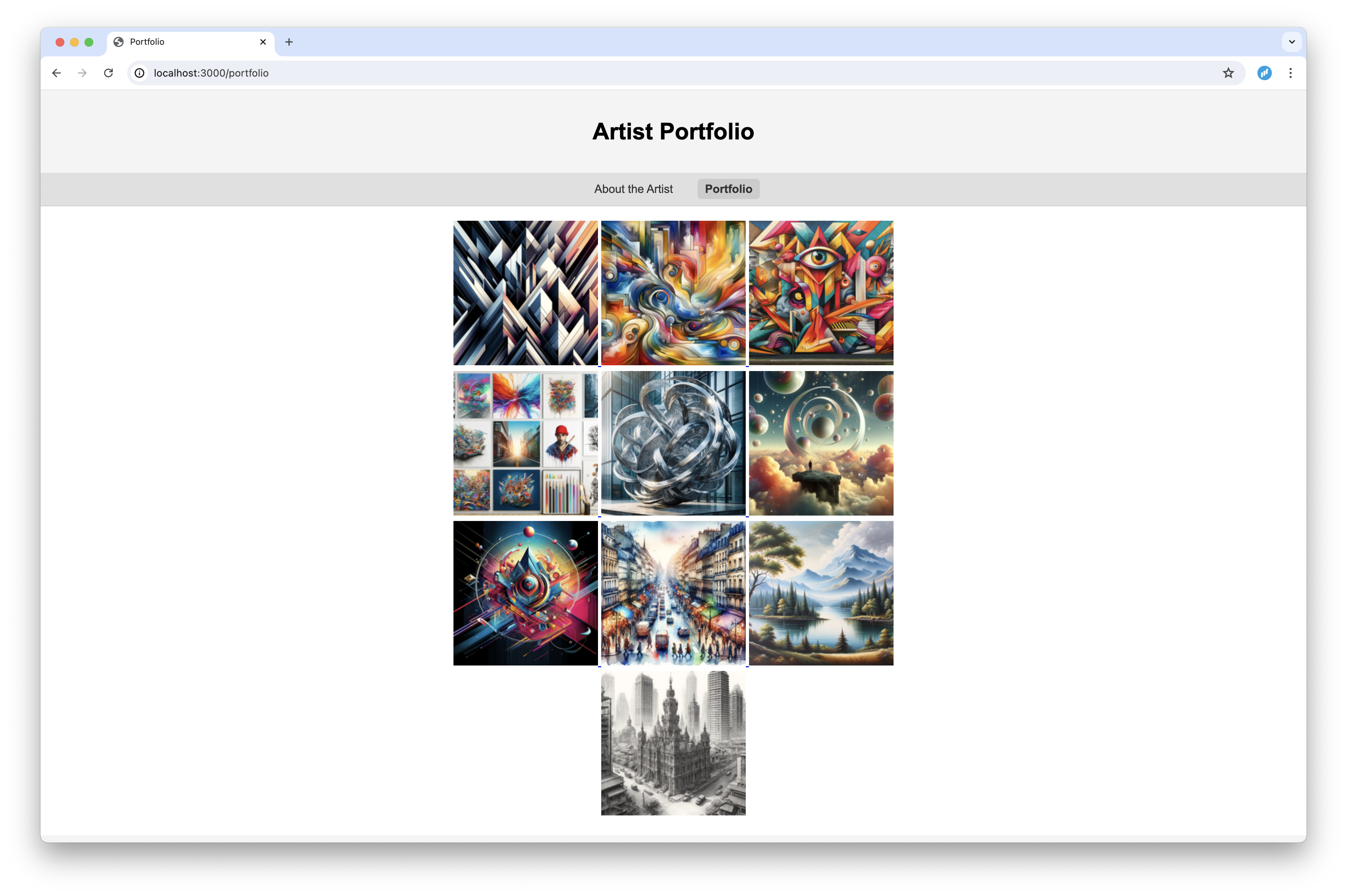
In this post, I'll show you how I built a simple artist portfolio site using this framework.
Setup
cargo new artist-portfolio
cd artist-portfolio
I added the following dependencies:
[dependencies]
axum = "0.7"
dotenv = "0.15"
tokio = { version = "1", features = ["full"] }
tower = "0.4"
tower-http = { version = "0.5", features = ["fs"] }
askama = "0.11"
tracing = "0.1"
tracing-subscriber = "0.3"
The code
First I created the main file, src/main.rs, which contains the application setup and the routes.
The repo is here.
// will show you the imported modules in a bit ...
mod handlers;
mod s3;
use axum::{Router, routing::get, extract::Extension};
use dotenv::dotenv;
use tower_http::services::ServeDir;
use tracing_subscriber;
use std::sync::Arc;
#[tokio::main]
async fn main() {
dotenv().ok();
tracing_subscriber::fmt::init();
// Initialize configuration
let aws_s3_bucket = std::env::var("AWS_S3_BUCKET").expect("AWS_S3_BUCKET must be set");
let config = Arc::new(Config { aws_s3_bucket });
let app = Router::new()
.route("/", get(handlers::about_handler))
.route("/portfolio", get(handlers::portfolio_handler))
.nest_service("/static", ServeDir::new("static"))
.layer(Extension(config.clone()));
let port = std::env::var("PORT").unwrap_or_else(|_| "3000".to_string());
let addr = std::env::var("BIND_ADDR").unwrap_or_else(|_| "0.0.0.0".to_string());
let bind_addr = format!("{}:{}", addr, port);
let listener = tokio::net::TcpListener::bind(&bind_addr).await.unwrap();
tracing::info!("Listening on {}", listener.local_addr().unwrap());
axum::serve(listener, app).await.unwrap();
}
#[derive(Clone)]
pub struct Config {
pub aws_s3_bucket: String,
}
- The
handlers module contains the request handlers for the different routes.
- The
s3 module contains the logic to interact with AWS S3 (I ended up simplifying this part for now, see in a bit).
- The
Config struct holds the configuration for the application (the AWS S3 bucket name holding the images). I'm using the Arc type to share this configuration across the application.
- The
dotenv crate is used to load environment variables from a .env file, see this article. I added an .env-template file in the repo to show you what variables you need to set.
- The
tracing and tracing-subscriber crates are used for logging.
- The
tower-http crate is used to serve static files from the static directory, which I happily got working for this app too.
- The
askama crate is used for templating, which I'll show that in the handlers section.
- The
tokio crate is used for async I/O.
- The
axum crate is the web framework itself and serves the application.
Creating the handlers
use askama::Template;
use axum::{
extract::Extension,
http::StatusCode,
response::Html,
};
use crate::Config;
use crate::s3::get_images;
use std::sync::Arc;
use std::collections::HashMap;
#[derive(Template)]
#[template(path = "about.html")]
struct AboutTemplate {
image_url: String,
current_page: &'static str,
}
pub async fn about_handler(Extension(config): Extension<Arc<Config>>) -> Result<Html<String>, StatusCode> {
let image_key = "artist.png";
let image_url = format!("https://{}.s3.amazonaws.com/{}", config.aws_s3_bucket, image_key);
let template = AboutTemplate { image_url, current_page: "home" };
match template.render() {
Ok(rendered) => Ok(Html(rendered)),
Err(_) => Err(StatusCode::INTERNAL_SERVER_ERROR),
}
}
#[derive(Template)]
#[template(path = "portfolio.html")]
struct PortfolioTemplate {
images: Vec<(String, String)>,
current_page: &'static str,
}
pub async fn portfolio_handler(Extension(config): Extension<Arc<Config>>) -> Result<Html<String>, StatusCode> {
let images = get_images(&config.aws_s3_bucket).unwrap_or_else(|_| HashMap::new());
// cannot get the template to work with a HashMap directly, so convert to a Vec of tuples
let images: Vec<(String, String)> = images.into_iter().collect();
let template = PortfolioTemplate { images, current_page: "portfolio" };
match template.render() {
Ok(rendered) => Ok(Html(rendered)),
Err(_) => Err(StatusCode::INTERNAL_SERVER_ERROR),
}
}
- The
handlers module contains the request handlers for the different routes.
- The
askama crate is used for templating. I created two templates, about.html and portfolio.html, which are rendered by the handlers.
- The
about_handler function renders the about.html template, passing the image URL and the current page name, which I use to highlight the current page in the navigation bar.
- The
portfolio_handler function renders the portfolio.html template, passing a list of image URLs and the current page name.
- The
s3::get_images function is a placeholder for now, returning a HashMap of image URLs from the S3 bucket. I'll show you how I implemented this function in the next section. I did have to convert the HashMap to a Vec of tuples to get the template to work, as I couldn't get it to work with a HashMap directly.
Retrieving images from AWS S3
use std::collections::HashMap;
use std::error::Error;
pub fn get_images(aws_s3_bucket: &str) -> Result<HashMap<String, String>, Box<dyn Error>> {
let mut images = HashMap::new();
// Hardcoded for now to keep it simple, but in a real-world scenario
// you would fetch the image URLs from an S3 bucket
for i in 1..=10 {
let full_image = format!("https://{}.s3.amazonaws.com/{}.webp", aws_s3_bucket, i);
let thumbnail = full_image.replace(".webp", "_thumb.png");
images.insert(full_image, thumbnail);
}
Ok(images)
}
- The
s3 module contains the logic to interact with AWS S3. I had this working at some point with the rusoto* crates, but I ended up simplifying it for this first iteration (old s3 code still here).
- For now I am just returning a
HashMap of image full + thumb URLs, but in a real-world scenario, you might fetch the images from a bucket (and only a few per request using pagination).
- I used ChatGPT to make some nice artist work images and made another Rust script to resize them (will post it soon here ...)
Templates and static files
I'm using the askama crate for templating. I created two templates, about.html and portfolio.html, which extend a base.html template. The about.html template contains some fake text about the artist, and the portfolio.html template displays a list of images.
{% extends "base.html" %}
{% block title %}About the Artist{% endblock %}
{% block content %}
<p>
Bunch of fake text about the artist.
</p>
{% endblock %}
This is the portfolio.html template:
{% extends "base.html" %}
{% block title %}Portfolio{% endblock %}
{% block content %}
<div class="image-container">
{% for (full_image, thumbnail) in images %}
<a href="#img{{ loop.index }}">
<img src="{{ thumbnail }}" alt="Artwork">
</a>
<div class="lightbox" id="img{{ loop.index }}">
<div class="lightbox-content">
<a href="#" class="close-lightbox">×</a>
<img src="{{ full_image }}" alt="Artwork">
</div>
</div>
{% endfor %}
</div>
{% endblock %}
Note here I only managed to loop through a Vec of tuples, not a HashMap directly, so I had to convert the HashMap to a Vec of tuples in the handler (see above).
I also added some CSS classes to the images and lightbox to make them look nice (you can find the CSS here). This is why you see a loop.index in the template, which is used to generate unique IDs for the lightbox.
And finally, the base.html template:
<!DOCTYPE html>
<html lang="en">
<head>
<meta charset="UTF-8">
<title>{% block title %}Artist Portfolio{% endblock %}</title>
<link rel="stylesheet" type="text/css" href="/static/style.css">
</head>
<body>
<header>
<h1>Artist Portfolio</h1>
</header>
<nav>
<a href="/" class="{% if current_page == "home" %}active{% endif %}">About the Artist</a>
<a href="/portfolio" class="{% if current_page == "portfolio" %}active{% endif %}">Portfolio</a>
</nav>
<div class="container">
{% block content %}{% endblock %}
</div>
<footer>
<p>© 2024+ Artist Portfolio</p>
</footer>
</body>
</html>
I like that apart from templating (and inheritance with them), I got static files to work so I could add a style.css file to style the page.
The static folder is served by the tower-http crate, which I added to the Router in the main file. It can also serve other static files like images, fonts, etc.
As mentioned before I also check each navigation item to see if it's the current page, and if so I add the active class to highlight it in the navigation bar.
Conclusion and next steps
I managed to build a simple artist portfolio site using Axum, a web framework for Rust. It's still a basic site, but I'm happy with the result so far 🚀
Of course I heavily used ChatGPT to get this working, but I learned so much faster this way, libraries like Axum and Askama make most sense when you start to use them in the context of a project.
Just reading about them won't get you anywhere near being able to use them effectively. There's still a lot to learn, but this gave me some good basic insights how to build a website with Rust. 💡
Again you can find the code in the repo.
I want to further explore how to interact with AWS S3, and I want to learn how to add a contact form to also handle form data and send emails. 📈
I also managed to deploy the site to Heroku, which I'll discuss soon here, it was really easy to do. 😍
What will you build with Axum? Reach out to me on social media, I'd love to hear about it ... 😎